LLM Benchmarks
How do you tell which LLMs are “better”? Numerous benchmarks are under development.
Prometheus-Eval: a family of open-source language models for evaluating other LLMs.
Other benchmarks:
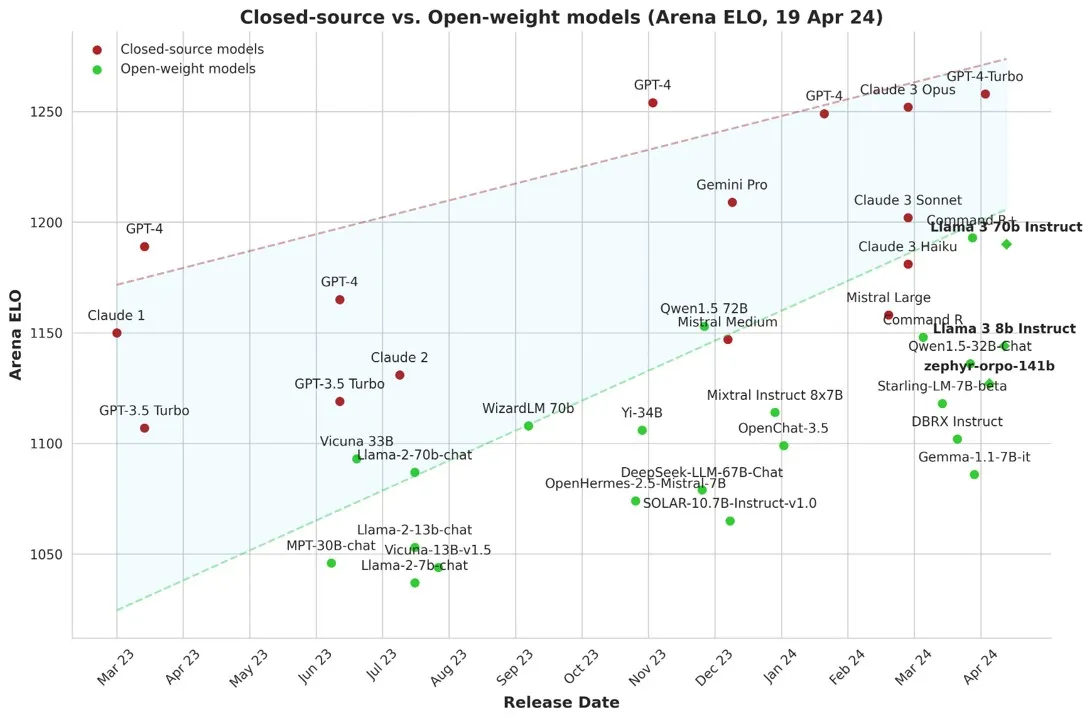
LMSYS Chatbot Arena Leaderboard
HuggingFace sponsors a crowdsourced ranking of LLMs
Contribute your vote 🗳️ at chat.lmsys.org! Find more analysis in the notebook.
Ranking as of Apr 8, 2024
| Rank | 🤖 Model | ⭐ Arena Elo | 📊 95% CI | 🗳️ Votes | Organization | License | Knowledge Cutoff |
|---|---|---|---|---|---|---|---|
| 1 | GPT-4-1106-preview | 1252 | +3/-3 | 56936 | OpenAI | Proprietary | 2023/4 |
| 1 | GPT-4-0125-preview | 1249 | +3/-4 | 38105 | OpenAI | Proprietary | 2023/12 |
| 4 | Bard (Gemini Pro) | 1204 | +5/-5 | 12468 | Proprietary | Online | |
| 4 | Claude 3 Sonnet | 1200 | +3/-4 | 40389 | Anthropic | Proprietary | 2023/8 |
| 10 | Command R | 1146 | +5/-6 | 12739 | Cohere | CC-BY-NC-4.0 | 2024/3 |
| 14 | Gemini Pro (Dev API) | 1127 | +4/-4 | 16041 | Proprietary | 2023/4 |
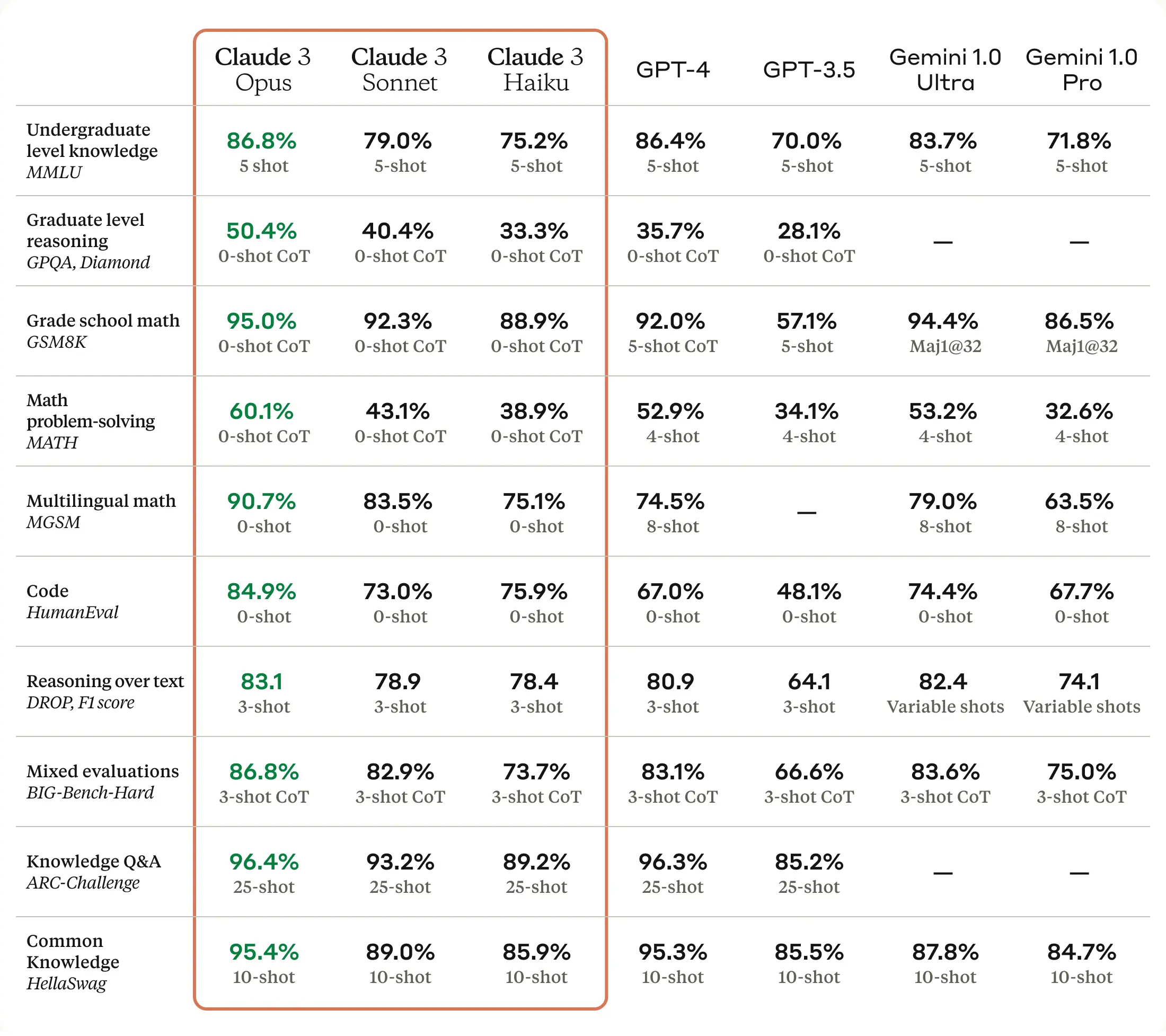
Anthropic released its Claude 3 model and says it beats its competitors
Benchmarking
Strange Loop Canon explains why it’s hard to evaluate LLMs: the same reason it’s hard to make a general-purpose way to evaluate humans.
Andrej Karpathy, a co-founder of OpenAI who is no longer at the company, agrees:
People should be extremely careful with evaluation comparisons, not only because the evals themselves are worse than you think, but also because many of them are getting overfit in undefined ways, and also because the comparisons made are frankly misleading.
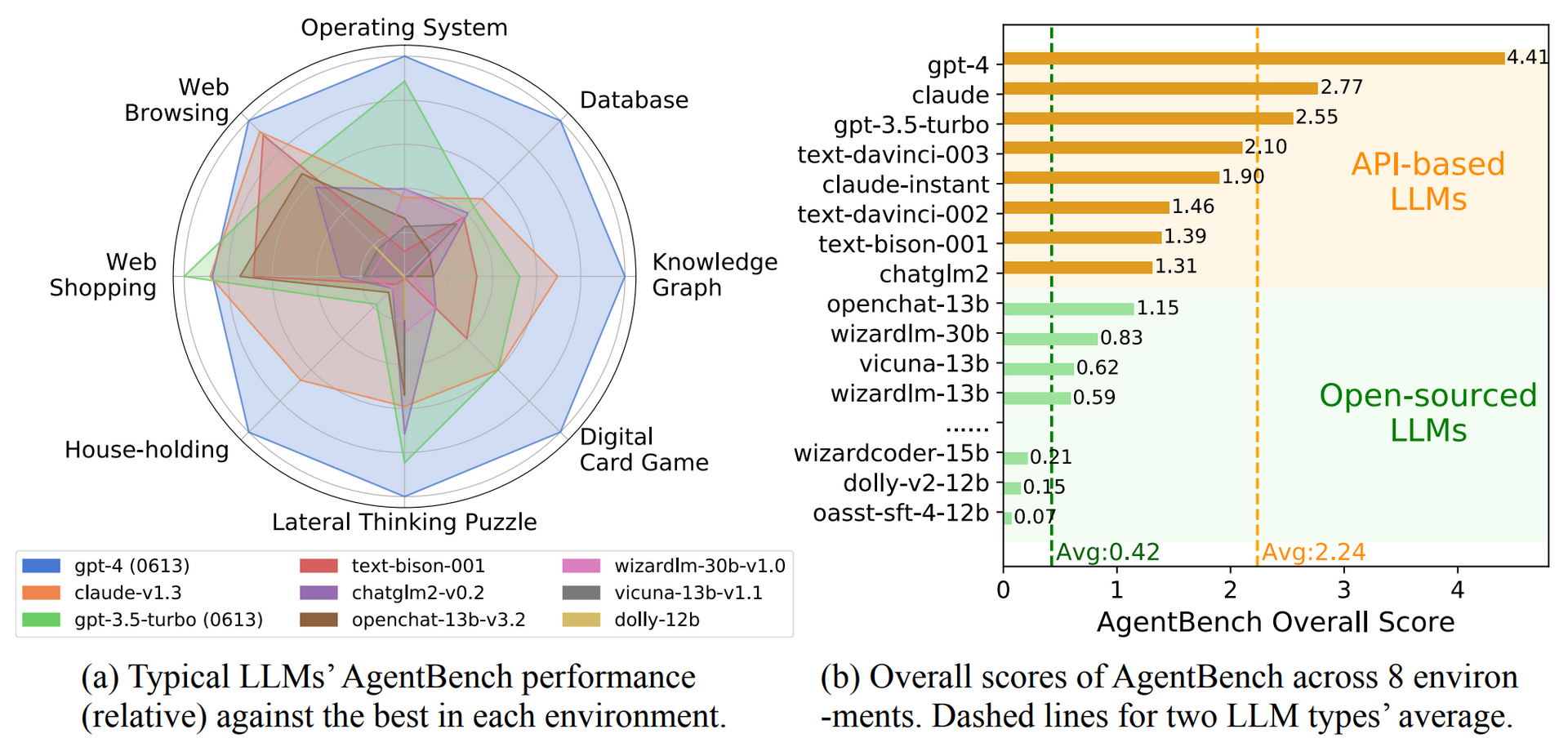
AgentBench is an academic attempt to benchmark all AI LLMs against each other.
Liu et al. (2023)
AgentBench, a multi-dimensional evolving benchmark that currently consists of 8 distinct environments to assess LLM-as-Agent’s reasoning and decision-making abilities in a multi-turn open-ended generation setting. Our extensive test over 25 LLMs (including APIs and open-sourced models)
The result: OpenAI’s GPT-4 achieved the highest overall score of 4.41 and was ahead in almost all disciplines. Only in the web shopping task, GPT-3.5 came out on top.
The Claude model from competitor Anthropic follows closely with an overall score of 2.77, ahead of OpenAI’s free GPT-3.5 Turbo model. The average score of the commercial models is 2.24.
see ($ The Decoder)
And Chris Coulson rates Azure vs OpenAI API speeds to show that Azure is approximately 8x faster with GPT-3.5-Turbo and 3x faster with GPT-4 than OpenAI.
For the most part you don’t have to worry about price differences between Azure and OpenAI, as the price is the same for all of their standard features. Prices are also quite affordable, especially GPT-3.5-Turbo, as running several rounds of testing only cost me a few cents.
Nicholas Carlini has a benchmark for large language models (GitHub) that includes a simple domain-specific language that makes it easy to add to the current 100+ tests. Most of these benchmarks evaluate the LLM for its coding capabilities.
- GPT-4: 49% passed
- GPT-3.5: 30% passed
- Claude 2.1: 31% passed
- Claude Instant 1.2: 23% passed
- Mistral Medium: 25% passed
- Mistral Small 21% passed
- Gemini Pro: 21% passed
A complete evaluation grid is available here.
Hugging Face has added four new leaderboards for measuring language models’ accuracy in answering questions relevant to businesses (finance, law, etc.), safety and security, freedom from hallucinations, and ability to solve reasoning problems. Unfortunately, the leaderboards only evaluate open source models.
Examining LLM performance on public benchmarks (10 minute read)
How overfit are popular LLMs on public benchmarks? New research from Scale AI SEAL revealed that Mistral & Phi are overfitting benchmarks, while GPT, Claude, Gemini, and Llama are not. The researchers produced a new eval GSM1k and evaluated public LLMs for overfitting on GSM8k.
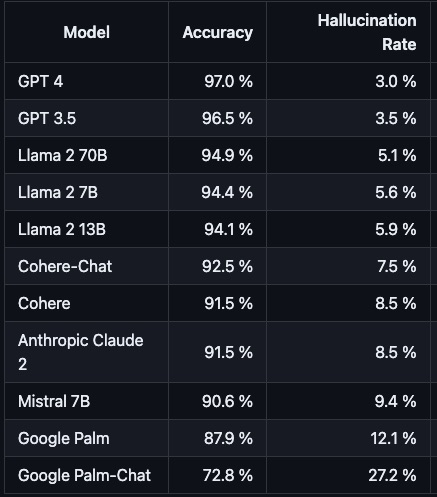
Hallucination
AI Hallucination Rate @bindureddy
DIY Benchmarking
^17b72a
A GitHub example of Evaluate LLMs in real time with Street Fighter III
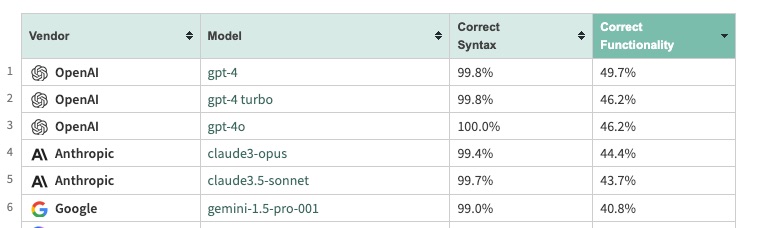
#coding
Wolfram LLM Benchmarking Project tries to go from English-language specifications to Wolfram Language code.
July 2024
See Also
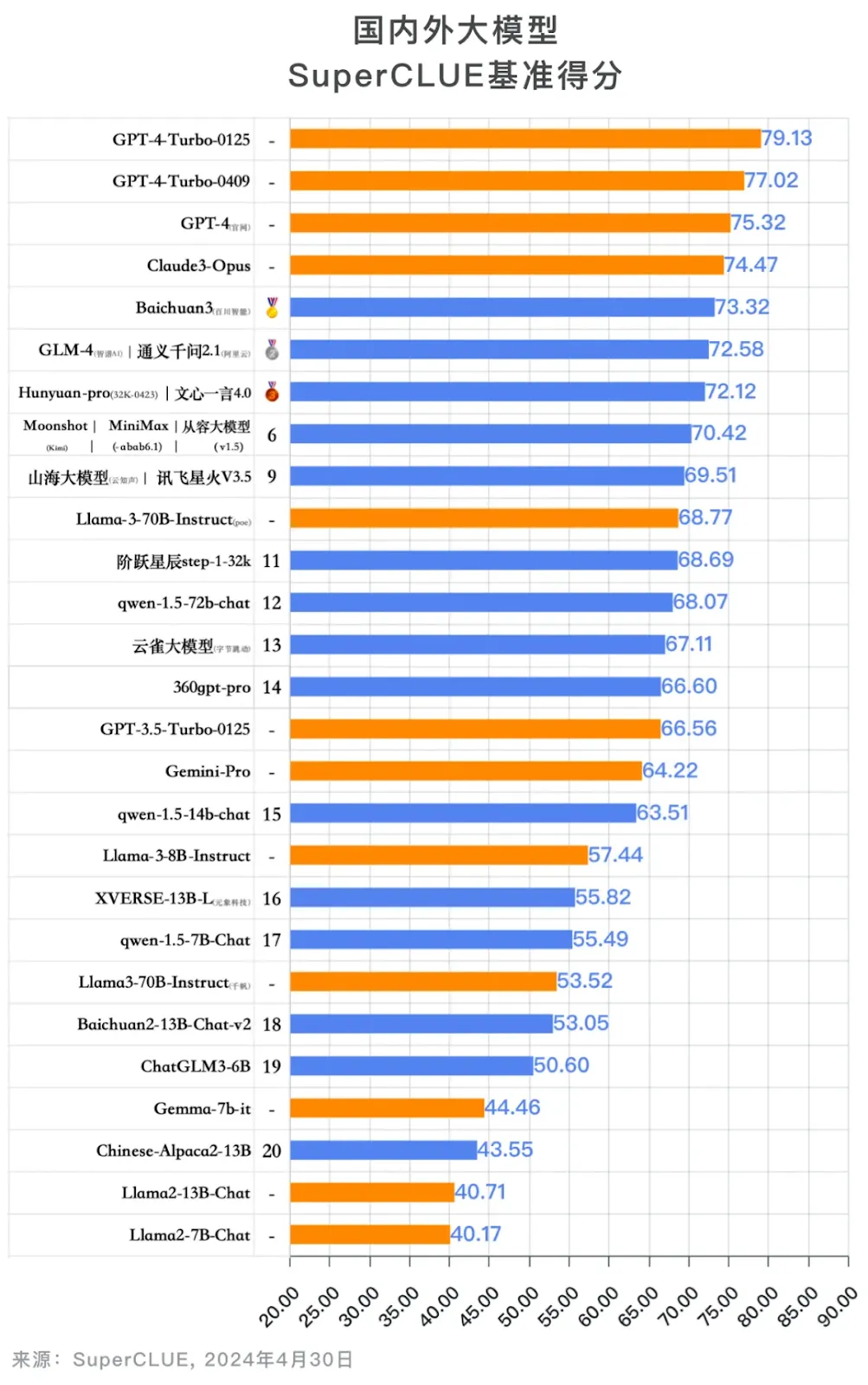
China LLM Benchmarks: Chinese LLMs are still far behind